Understanding probability theory often feels like a daunting task for students and professionals alike. Whether you are analyzing quality control data or predicting project outcomes, having the right tools makes a significant difference. Our Binomial Distribution Calculator provides a seamless way to compute complex statistical values without the need for manual formulas.
This digital resource simplifies the process of finding probability mass functions and cumulative distribution functions. By entering your specific parameters, you receive accurate results in seconds. Efficiency is key when you are working under tight deadlines or managing large datasets.
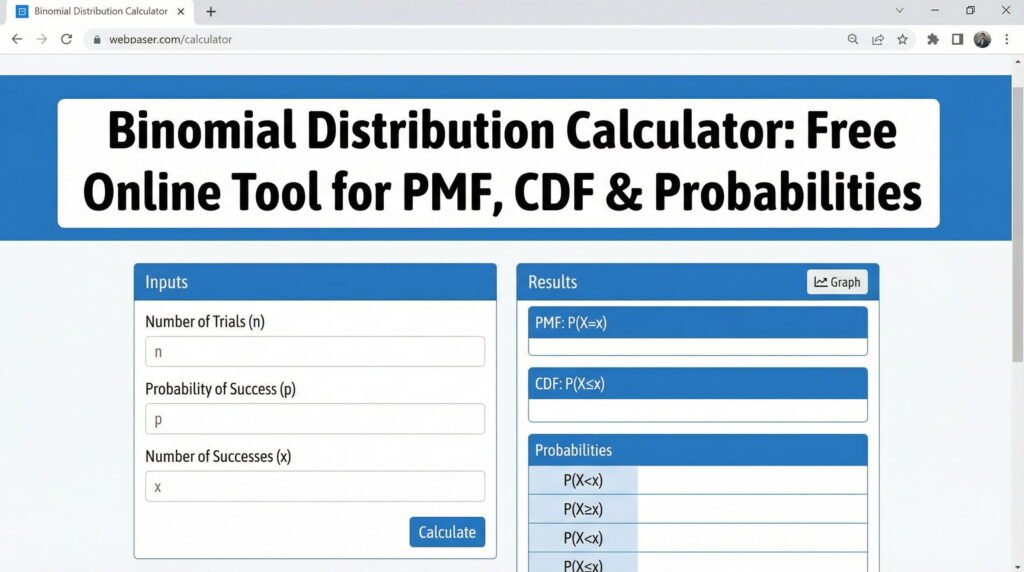
We designed this platform to bridge the gap between abstract mathematical concepts and practical application. You can now focus on interpreting your findings rather than getting lost in tedious arithmetic. Explore how this tool transforms your workflow and enhances your statistical accuracy today.
Key Takeaways
- Access precise probability mass function results instantly.
- Simplify complex statistical computations for academic or professional projects.
- Understand cumulative distribution functions with user-friendly inputs.
- Save valuable time by automating repetitive mathematical tasks.
- Improve your data analysis accuracy with reliable online tools.
Understanding the Binomial Distribution Calculator
At the heart of probability theory lies the concept of the binomial distribution. This mathematical model describes the number of successes in a fixed sequence of independent experiments. Each trial results in one of two possible outcomes, typically labeled as success or failure.
Because manual calculations can become tedious and prone to error, a specialized calculator serves as an essential bridge between abstract theory and practical application. It allows users to input specific variables to generate precise statistical data instantly. By automating the math, the tool ensures that your results remain accurate and reliable for any project.
The binomial distribution calculator is designed to handle various parameters with ease. Whether you are analyzing quality control in manufacturing or predicting outcomes in clinical trials, the software processes your inputs to provide meaningful insights. Key features of this tool include:
- Precision: Eliminates rounding errors common in manual computation.
- Efficiency: Provides instant results for complex datasets.
- Versatility: Supports a wide range of trial counts and probability values.
By leveraging this binomial distribution tool, you can focus on interpreting your findings rather than struggling with complex formulas. It transforms raw numbers into actionable intelligence, making it a vital asset for students, researchers, and data analysts alike. Embracing this technology simplifies the way you approach probability and statistical modeling.
Binomial Distribution Formula Explained
Mastering the binomial distribution requires a solid grasp of its underlying mathematical framework. Providing a clear formula with explanation helps bridge the gap between abstract theory and practical application. By understanding these components, you can determine the likelihood of specific outcomes in experiments with two possible results.
Breaking Down the Combination Formula
At the heart of this calculation lies the combination formula c(n, x), which determines the number of ways to achieve a specific number of successes. This part of the equation accounts for the different sequences in which successes and failures can occur. It ensures that every possible arrangement is considered during the analysis.
“Mathematics is the language in which God has written the universe.”
Galileo Galilei
When you learn how to calculate this value, you are essentially finding the number of subsets of size x that can be drawn from a set of n items. This is often expressed as n! / (x!(n-x)!). Understanding this coefficient is vital for accurate probability modeling.
Variables and Parameters in the Equation
The complete binomial equation combines the combination coefficient with the probability of success and failure. The variable n represents the total number of independent trials performed. Meanwhile, x denotes the specific number of successful outcomes you wish to measure.
The parameter p represents the probability of success on any single trial. Conversely, (1-p) represents the probability of failure. By multiplying these components together, you arrive at the final probability for a given scenario.
| Variable | Definition | Role |
|---|---|---|
| n | Total Trials | Sample size |
| x | Successes | Target outcome |
| p | Probability | Success rate |
BinomPDF vs BinomCDF: What is the Difference?
Choosing the right tool for your probability problem starts with knowing whether you need a single point or a range. Many users often ask, “what’s the difference” when they encounter these two common statistical functions. While both relate to binomial experiments, they serve distinct purposes in data analysis.
Understanding these functions is critical for selecting the correct statistical approach in any software environment. Using the wrong one can lead to significant errors in your final results.
When to Use Probability Mass Function
The probability mass function, commonly known as binompdf, calculates the probability of obtaining an exact number of successes in a fixed number of trials. You should use this function when you need to find the likelihood of one specific outcome occurring.
For example, if you want to know the probability of flipping exactly five heads in ten coin tosses, this is your go-to tool. It provides the probability for a single, discrete point on the distribution graph.
“Statistics is the grammar of science, and knowing your functions is the first step toward fluency.”
When to Use Cumulative Distribution Function
The cumulative distribution function, or binomcdf, calculates the probability of obtaining a range of successes. Instead of looking at one point, it sums the probabilities of all outcomes from zero up to a specified value.
You should use this function when your research question involves phrases like “at most” or “less than.” It is highly effective for determining the likelihood of a threshold being met or exceeded.
Consider these key differences when deciding which function to apply:
- Binompdf is for exact values (e.g., exactly 3 successes).
- Binomcdf is for ranges (e.g., 3 or fewer successes).
- Always verify your input parameters to ensure the software processes the correct range.
Interactive Binomial Distribution Tool
Statistical analysis is often daunting, but our interactive calculator makes the process intuitive and efficient. By providing a Binomial Distribution Calculator directly in your browser, we eliminate the need for complex manual computations. This tool serves as a bridge between raw data and actionable insights.
How to Input Trials and Success Probability
To begin your analysis, you must define the core parameters of your experiment. First, enter the number of trials, which represents the total count of independent events you are observing. Next, input the success probability, expressed as a decimal between zero and one.
Finally, specify the exact number of successes you wish to evaluate. Once these values are entered, the system instantly generates the probability mass function and cumulative distribution results. This streamlined approach ensures that you spend less time on arithmetic and more time on interpreting your findings.
“Statistics is the grammar of science, providing the structure necessary to turn observations into meaningful knowledge.”
— Anonymous
Interpreting Mean and Standard Deviation Results
Understanding the distribution shape requires looking at the mathematical concepts mean (np) and standard deviation (√np(1-p)). The mean tells you the expected number of successes over the long run. It acts as the central anchor for your probability model.
The standard deviation provides a measure of how much your results might vary from that average. A smaller value indicates that your outcomes are tightly clustered around the mean. Conversely, a larger value suggests a wider spread of potential results, which is vital for assessing risk and reliability in your data.
Number of Trials (n): Success Probability (p): Successes (x): Calculate
function calculate() { const n = parseInt(document.getElementById(‘n’).value); const p = parseFloat(document.getElementById(‘p’).value); const x = parseInt(document.getElementById(‘x’).value); const mean = n * p; const stdDev = Math.sqrt(n * p * (1 – p)); document.getElementById(‘result’).innerHTML = “Mean: ” + mean.toFixed(2) + “
Std Dev: ” + stdDev.toFixed(2); }
Bernoulli Trials and the Foundation of Probability
At the heart of every complex probability model lies the simple yet powerful concept of the bernoulli trial. This fundamental unit serves as the building block for the entire binomial distribution framework. By breaking down larger experiments into smaller, manageable parts, statisticians can predict outcomes with high precision.
Defining Independent Events
A core requirement for any bernoulli trial is the principle of independence. This means that the outcome of one specific event must not influence the result of any subsequent events. If the probability of an event changes based on previous results, the model loses its predictive power.
Consistency is the key to maintaining this independence throughout a series of trials. When each event remains isolated, the mathematical integrity of the entire sequence is preserved. This allows researchers to apply standard formulas without worrying about hidden variables or external dependencies.
The Role of Success and Failure Outcomes
Every bernoulli trial is strictly limited to exactly two possible outcomes: success or failure. This binary structure simplifies complex real-world scenarios into a format that is easy to calculate and analyze. Whether you are flipping a coin or testing a product for defects, the logic remains the same.
Success is typically defined as the occurrence of the event you are tracking, while failure represents everything else. By assigning a fixed probability to success, you create a stable environment for statistical modeling. Mastering this bernoulli trial concept is essential for anyone looking to apply probability theory to practical, everyday challenges.
Cumulative Binomial Distribution Table
Understanding the cumulative binomial distribution table provides a foundational look at how we calculate outcomes for a discrete distribution. Before the widespread availability of high-speed computing, these printed grids were the primary resource for researchers and students alike.
Reading Probability Tables for Discrete Variables
To use these tables effectively, you must first identify the specific random variable associated with your experiment. The table is typically organized by the number of trials and the probability of success, requiring you to locate the intersection of these values.
Once you find the correct section, you look for the specific quantile that represents your threshold. By matching the number of successes to the corresponding column, you can determine the cumulative probability for your data set. This manual process requires careful attention to detail to ensure the correct row is selected.
“The beauty of statistical tables lies in their ability to make complex probability theory accessible to everyone, regardless of their access to advanced technology.”
Limitations of Static Tables vs Online Calculators
While static tables are useful for learning, they suffer from significant limitations in modern practice. They often lack the granularity needed for precise calculations, as they only provide values for specific, rounded probabilities. Furthermore, searching through pages of data is time-consuming compared to the instant results provided by digital tools.
Online calculators offer superior flexibility by allowing users to input any random variable or probability without being restricted to pre-printed values. They also eliminate the risk of human error associated with manual lookups. The following table highlights the key differences between these two approaches for analyzing a discrete distribution.
| Feature | Static Table | Online Calculator |
|---|---|---|
| Precision | Limited to printed values | High (decimal accuracy) |
| Speed | Slow manual lookup | Instantaneous |
| Flexibility | Fixed parameters only | Customizable inputs |
| Portability | Physical book required | Accessible via web |
Normal Approximation to Binomial Distribution
The normal approximation offers a powerful shortcut for estimating probabilities when dealing with a large number of trials. While the binomial distribution is inherently discrete, it begins to resemble a smooth bell curve as the sample size increases. This transition allows researchers to use the properties of the sampling distribution to simplify complex calculations that would otherwise require intensive computation.
Conditions for Using the Normal Approximation
To ensure your estimates remain accurate, you must verify specific criteria before applying this method. The most common rule of thumb requires that both the expected number of successes and failures be sufficiently large. Specifically, the product of the number of trials and the probability of success must be at least five or ten.
If these conditions are not met, the distribution remains too skewed for the normal approximation to provide reliable results. Checking these thresholds ensures that the sampling distribution maintains the symmetry required for valid statistical inference. When these requirements are satisfied, the binomial model effectively mirrors the behavior of a continuous normal curve.
“The normal distribution is the most important probability distribution in statistics because it describes the distribution of many natural phenomena.”
Applying Continuity Correction Factors
Because you are using a continuous curve to estimate a discrete binomial distribution, you must account for the gap between these two models. This is where the continuity correction factor becomes essential. By adding or subtracting 0.5 from your discrete value, you capture the entire area of the bar in a histogram, which significantly improves the precision of your estimate.
Applying this adjustment is a critical step in bridging the gap between discrete outcomes and continuous probability density functions. Without this correction, your results may suffer from systematic bias. The following table highlights the key differences between these two approaches to help you choose the right tool for your data.
| Feature | Binomial Distribution | Normal Approximation |
|---|---|---|
| Data Type | Discrete | Continuous |
| Calculation | Exact Formula | Z-score/Area under curve |
| Complexity | High for large n | Low for large n |
| Correction | Not required | Continuity factor needed |
Solved Examples for Practical Application
Mastering probability requires practice, so let us walk through some solved examples together. By applying the binomial formula to specific datasets, you can verify your understanding of how variables interact. These exercises serve as a bridge between theoretical concepts and real-world data analysis.
Calculating Probability for n=20 and p=0.70
Consider a scenario where you conduct 20 independent trials with a success probability of 0.70. To find the likelihood of exactly 14 successes, you must follow a step-by-step solution. First, identify the variables: n=20, k=14, and p=0.70.
Next, input these values into the binomial formula or your preferred calculator. The calculation determines the probability mass function for this specific outcome. You will find that the result represents the precise chance of achieving exactly 14 successes in 20 attempts.
Calculating Probability for n=10 and p=0.10
In this second scenario, we examine a lower success rate. Suppose you have 10 trials and a success probability of 0.10. If you want to find the probability of achieving 2 or fewer successes, you must use the cumulative distribution function.
This step-by-step solution involves summing the probabilities for k=0, k=1, and k=2. By aggregating these individual outcomes, you arrive at the total cumulative probability. This method is essential for understanding the likelihood of a range of events rather than a single point.
| Scenario | Trials (n) | Probability (p) | Target (k) |
|---|---|---|---|
| High Success | 20 | 0.70 | 14 |
| Low Success | 10 | 0.10 | 0 to 2 |
| Baseline | 5 | 0.50 | 3 |
Comparing Binomial Distribution to Related Models
Understanding how different probability distributions relate to one another improves your analytical precision. While the binomial model is a staple in statistics, other frameworks often provide a better fit depending on your specific data collection method.
Selecting the right tool ensures that your conclusions remain valid and reliable. Each model serves a unique purpose based on the nature of the events being studied.
Poisson Distribution vs Binomial Distribution
The poisson distribution is frequently confused with the binomial model, yet they serve different purposes. While the binomial model tracks the number of successes in a fixed number of trials, the poisson distribution models the number of events occurring within a fixed interval of time or space.
You should choose the binomial model when you have a set number of trials and a known probability of success. Conversely, use the Poisson model when dealing with rare, independent events where the total number of potential trials is effectively infinite.
Geometric and Negative Binomial Distributions
When your research focuses on the timing of successes rather than the total count, you might look toward the geometric distribution. This model calculates the probability of the first success occurring on a specific trial number.
For more complex scenarios, related distributions negative binomial models are highly effective. This distribution tracks the number of trials required to achieve a predetermined number of successes.
It is also helpful to consider the hypergeometric distribution when your sampling process occurs without replacement. Unlike the binomial model, which assumes constant probability, the hypergeometric model accounts for changing probabilities as the population size decreases.
| Distribution | Primary Use Case | Key Characteristic |
|---|---|---|
| Binomial | Fixed trials | Constant probability |
| Geometric | First success | Variable trial count |
| Hypergeometric | Sampling without replacement | Changing probability |
Advanced Statistical Tools and Software Integration
Mastering binomial distribution requires more than just a browser; it demands familiarity with industry-standard tools and programming environments. As your data analysis needs grow, integrating advanced statistical platforms becomes a necessary step for accuracy and efficiency. These professional resources allow for deeper insights and faster processing of complex probability models.
Using TI-84 Calculators for Binomial Problems
For many students, the ap statistics calculator is a staple in the classroom. The TI-84 series remains one of the most reliable tools & platforms ti-84 users depend on for quick, on-the-go computations. These devices feature built-in distribution menus that simplify the process of finding specific probability values without manual formula entry.
By navigating to the distribution menu, you can easily select functions for probability mass or cumulative distribution. This hardware approach is particularly useful during timed assessments where internet access is restricted. Reliability and speed are the primary advantages of using these dedicated handheld devices for academic success.
Leveraging Excel, Python, and R for Statistics
When working with large datasets, professional software provides superior flexibility compared to basic calculators. In spreadsheet environments, the excel binom.dist function allows users to compute probabilities directly within their data tables. This integration makes it simple to visualize trends and perform batch calculations across thousands of rows.
“The ability to automate statistical analysis through programming is the hallmark of a modern data scientist, turning raw numbers into actionable intelligence.”
For those involved in advanced research, python scipy offers a comprehensive library for scientific computing, including specialized modules for discrete distributions. Similarly, r statistics is widely considered the gold standard for academic and professional statistical modeling. These programming environments provide the precision required for complex simulations and high-level data processing tasks.
Hypothesis Testing and Confidence Intervals
Beyond simple probability calculations, the binomial distribution serves as a cornerstone for rigorous hypothesis testing. Researchers often use these methods to determine if an observed proportion deviates significantly from an expected value. By applying these statistical tests, you can transform raw data into actionable insights with a high degree of mathematical confidence.
Performing a Binomial Test
The binomial test is an exact test used to determine whether the proportion of successes in a sample differs from a hypothesized population proportion. It is particularly useful when your sample size is small or when the assumptions for normal approximation are not met. You start by defining a null hypothesis, which assumes that the observed success rate is equal to the expected probability.
Once the null hypothesis is set, you calculate the probability of observing your specific result or one even more extreme. This process allows you to evaluate the strength of your evidence against the null. If the result is highly unlikely under the null hypothesis, you may reject it in favor of an alternative explanation.
Determining Significance with P-values
The p-value acts as the primary metric for determining statistical significance in these experiments. A low value typically indicates that your results are unlikely to have occurred by random chance alone. When the p-value falls below your chosen alpha level, usually 0.05, you conclude that the effect is statistically significant.
While the binomial test is ideal for binary data, researchers sometimes compare it to the chi-square test. The chi-square test is often used for larger samples where the normal approximation is appropriate. Constructing a confidence interval alongside these tests provides a range of plausible values for the true population proportion, offering a more complete picture than a single point estimate.
| Test Type | Data Requirement | Best Use Case |
|---|---|---|
| Binomial Test | Binary (Success/Failure) | Small sample sizes |
| Chi-square Test | Categorical Frequencies | Large sample sizes |
| Confidence Interval | Proportional Data | Estimating range of accuracy |
Always remember that a confidence interval helps quantify the uncertainty inherent in your sample. By combining these tools, you ensure that your statistical conclusions remain robust and reliable across various research scenarios.
Conclusion
Modern statistical analysis relies on the balance between deep conceptual knowledge and the speed of digital computation. Mastering the binomial distribution requires a firm grasp of the underlying mathematical principles alongside the practical application of online tools. These resources bridge the gap between complex theory and real-world decision-making.
Digital calculators provide immediate accuracy for probability mass functions and cumulative distribution functions. Relying on these tools allows researchers to focus on interpreting data trends rather than performing repetitive manual arithmetic. Efficiency in your workflow improves when you integrate these calculators into your standard statistical practice.
Continued exploration of these probability concepts builds confidence in your analytical skills. Apply these methods to your own datasets to see how variables like trial counts and success probabilities influence your outcomes. Consistent practice with these examples ensures you remain proficient in evaluating discrete random variables across various professional fields.
Share your experiences with these tools or reach out with questions about specific probability scenarios. Engaging with the broader statistical community helps refine your understanding of these essential mathematical models. Keep testing your hypotheses and refining your models to achieve the best possible results in your future projects.
FAQ
What is the binomial distribution and when should I use it?
The binomial distribution is a discrete distribution used to model the number of successes in a fixed number of trials (n), where each trial has the same success probability (p). You should use it when your data consists of independent events that result in a simple binary outcome: success or failure. This is the mathematical foundation for analyzing a series of a Bernoulli trial.
What’s the difference between binomPDF and binomCDF?
The main distinction lies in the range of the random variable. Use binompdf (Probability Mass Function) when you need to calculate the probability of an exact number of successes. Use binomcdf (cumulative distribution function) when you need to find the probability of a range, such as “at most” or “less than” a certain number of successes. These functions are standard in tools like the TI-84 and AP statistics calculator.
How do I calculate the mean and standard deviation for a binomial distribution?
To find the expected value, use the formula for the mean (np), which is the number of trials multiplied by the probability of success. To measure the spread or variability, calculate the standard deviation (√np(1-p)). These mathematical concepts are essential for understanding the sampling distribution of your data.
Can you provide a binomial distribution formula with explanation?
Certainly. The formula is P(x) = c(n, x) * p^x * (1-p)^(n-x). In this step-by-step solution, c(n, x) represents the combination formula, which determines the number of ways to arrange x successes in n trials. The variable p is the success probability, and (1-p) is the failure probability. This allows you to calculate the probability mass function for any given quantile.
How do I perform binomial calculations in software like Excel or Python?
In Microsoft Excel, you can use the excel binom.dist function to find both individual and cumulative probabilities. For those using Python SciPy, the `scipy.stats.binom` module provides comprehensive methods for PMF and CDF. If you are working within R statistics, functions like `dbinom()` and `pbinom()` are the standard tools for these statistical tests.
When is it appropriate to use a normal approximation to the binomial distribution?
You can use a normal approximation when the sample size is large enough—typically when both np and n(1-p) are greater than or equal to 5 or 10. This method approximates the binomial discrete distribution using a continuous curve, which simplifies calculations for a large number of trials. Remember to apply a continuity correction for the most accurate results.
How does the binomial distribution differ from a Poisson or geometric distribution?
While the binomial distribution counts successes in a fixed number of trials, the Poisson distribution counts occurrences over a fixed interval of time or space. The geometric distribution calculates the number of trials until the *first* success occurs. Other related models include the negative binomial (trials until a specific number of successes) and the hypergeometric distribution (sampling without replacement).
What is a binomial test and how does it involve a p-value?
A binomial test is a type of hypothesis testing used to determine if the observed distribution of a binary variable deviates from a theoretical expectation. The resulting p-value tells you the probability of obtaining your results (or more extreme results) assuming the null hypothesis is true. This is often used to construct a confidence interval for a proportion or to compare against a chi-square test in categorical data analysis.
Are there solved examples for specific trial sets like n=20 and p=0.70?
Yes. For n=20 and p=0.70, the mean is 14 (20 * 0.70) and the variance is 4.2. Using the combination formula, the probability of exactly 15 successes is calculated as c(20, 15) * 0.70^15 * 0.30^5. These types of solved examples help demonstrate how to apply the theoretical formula with explanation to real-world data points.